一、前言
最近看文献看到这么一张图:

作者对单细胞数据整合的方法做了benchmarking,然后这张图就是整体展示一下这几个方法的表现。正好我目前的课题也需要类似的图,于是研究了一下这张图是用什么方法做的。结果找到了一个叫funkyheatmap的包。看了下它的教程,感觉很简单,就是只要把数据按照它需求的格式整理好,然后一行代码就能解决了。但真正上手后才发现事情远远没有那么简单。这里开篇博文,记录一下自己对这个方法的探索过程。
二、简单版介绍
测试数据可以从这里获取:点击链接获取测试数据。
接下来我将以我的数据格式和需求来具体讲一讲这个工具到底怎么用。在讲之前我先提前说一下,这个东西用起来有2个难点(当然简单版就1个),第一个难点是数据准备,想要把你的数据弄成它需要的格式还是挺麻烦的一件事,尤其如果你对dyplr之类的包不熟悉的话。第2个难点就是个性化出图了,这个放到第三节来讲。先来说说简单版的,也就是它出什么图你就用什么图,不作任何修改。
假设我手上有一个长数据,大概长这样:
| Dataset | Type | AUC | ACC | Tool |
|---|---|---|---|---|
| DataSet1 | T1 | 0.77 | 0.68 | Tool A |
| DataSet2 | T2 | 0.85 | 0.72 | Tool B |
| DataSet3 | T3 | 0.65 | 0.59 | Tool C |
我的数据里包含了Dataset,Type,AUC,ACC,Tool这几列。我这里的的需求是,首先图的样子要跟上面示例图差不多。行很简单,代表着每个数据集,那列呢?首先得有一列是Dataset列,放着Dataset的ID。其次有Type列,放着type的名称。这几个在上面示例图就相当于它的Name和feature列。紧接着后面就是各种统计图了,这里我跟示例图一样,也希望用横向条形图展示。根据示例图我们可以得出,我的图的条形图部分可以分为两块,AUC和ACC。每个部分包含每个Tool在每个Dataset的AUC和ACC的表现。最后,条形图上面还得显示横向比较的排名,也就是在同一Dataset中,对每个方法的出的AUC和ACC分别进行排名,然后显示在图上。
搞清楚这些后,我们就先来处理数据吧:
# 加载相关的包
library(funkyheatmap)
library(dplyr)
library(tibble)
library(tidyr)
library(ggplot2)
setwd('/path/to/your/dataset/')
data <- read.csv('funkyheatmap.csv', header = T)
# 这一步直接把长数据转成宽数据 (当时写代码的时候有点迷糊,变量名其实应该叫data_wide,anyway,知道意思就行)
data_long <- data %>%
pivot_longer(cols = c(AUC, ACC), names_to = "Metric", values_to = "Value") %>%
unite("Tool_Metric", Tool, Metric, sep = "_") %>%
pivot_wider(names_from = Tool_Metric, values_from = Value)
经过转换后,我们现在的数据长这样:

我们发现AUC和ACC值是相隔开的,我们接下来需要把AUC和AUC放一块,ACC和ACC放一块:
data_long <- data_long %>%
select(Dataset, DataType,
ends_with("_AUC"),
ends_with("_ACC"))

然后,我们需要来生成其对应的排名,这里需要对数据框做稍微复杂一点点的处理,原因是后面的作图需求,我在作图部分再解释,这里直接说结果,就是我们要把每个Tool的AUC和ACC其对应的排名放在该指标的后面一列。例如,Tool_A_AUC的排名,就放在其后方,Tool_B_AUC列前方,以此类推。随后,我这里还做了一个设置,就是仅给排名top 3的值赋予Ranking value。同时,如果某个Dataset的AUC或ACC中含有NA值,那排名时不考虑NA值直接进行排名。通过以下代码,我们来生成每个指标的排名:
# 自定义排名函数:值为 NA 或 0 时不参与排名
custom_rank <- function(x) {
x[is.na(x) | x == 0] <- NA # 将 NA 或 0 保留为 NA
ranks <- rank(-x, na.last = "keep", ties.method = "min") # 按从大到小排序
ranks[ranks > 3] <- NA # 排名超过 3 的值设置为 NA
return(ranks)
}
insert_rank_columns_by_row <- function(df, suffix = "", rank_suffix = "") {
col_names <- grep(suffix, colnames(df), value = TRUE) # 找到目标列
# 对每一行计算排名
rank_matrix <- t(apply(df[col_names], 1, custom_rank)) # 每行排名
# 动态插入排名列
for (col in rev(col_names)) { # 从后往前插入,避免索引混乱
rank_col <- paste0(rank_suffix, col) # 构造排名列名
col_index <- which(colnames(df) == col) # 找到当前列索引
# 插入排名列前后部分
if (col_index < ncol(df)) {
df <- cbind(
df[, 1:col_index, drop = FALSE], # 插入前部分
setNames(as.data.frame(rank_matrix[, which(col_names == col), drop = FALSE]), rank_col), # 插入排名列
df[, (col_index + 1):ncol(df), drop = FALSE] # 插入后部分
)
} else {
df <- cbind(
df[, 1:col_index, drop = FALSE], # 插入前部分
setNames(as.data.frame(rank_matrix[, which(col_names == col), drop = FALSE]), rank_col) # 插入排名列
)
}
}
return(df)
}
data_long <- insert_rank_columns_by_row(data_long, suffix = "_AUC", rank_suffix = "ranked_")
data_long <- insert_rank_columns_by_row(data_long, suffix = "_ACC", rank_suffix = "ranked_")
# # 如果你的AUC和ACC中有NA值的话最好执行一次以下代码,将 AUC和ACC中的NA 替换为 0
# #data_long[, 3:10][is.na(data_long[, 3:10])] <- 0
# fill_na_conditionally <- function(df, start_col, end_col, exclude_prefix = "ranked") {
# # 筛选目标列名:列范围在 start_col 到 end_col 且不以 exclude_prefix 开头
# target_cols <- colnames(df)[start_col:end_col]
# target_cols <- target_cols[!grepl(paste0("^", exclude_prefix), target_cols)]
#
# # 填充 NA 为 0
# df[target_cols] <- lapply(df[target_cols], function(col) {
# ifelse(is.na(col), 0, col)
# })
#
# return(df)
# }
# data_long <- fill_na_conditionally(data_long, start_col = 3, end_col = 18, exclude_prefix = "ranked")
这样每个指标就按照行生成了其对应的排名,此时data_long一共有18列:

接下来有个细节步骤一定要做,就是把这个data_long给他ungroup,不然作图就会报错,因为它默认把ID当作group,就这一步卡了我半天:
#一定要取消group
data_long <- data_long %>% ungroup()
# 不确定可以用groups(data_long)查看ungroup成功没有
# 如果成功的话应该会显示list()
随后就是作图另一个关键步骤了,生成你的data_long中每一列的信息,用于后续作图。这里要声明你每一列数据希望它以什么方式呈现,以及分组,颜色等等一堆信息:
# 创建 column_info
column_info <- data.frame(
id = names(data_long),
group = c("Dataset", "DataType",
rep(c("AUC",""), length.out = 8),
rep(c("ACC",""), length.out = 8)
),
name = c('','',rep(c('Tool A','','Tool B','',
'Tool C','','Tool D',''), 2)
),
geom = c("text", "text",
rep(c("bar","text"), length.out = 16)
),
palette = c(NA, NA, # 前两列不需要调色板
rep(c("AUC_palette",NA), length.out = 8),
rep(c("ACC_palette",NA), length.out = 8)
),
options = I(c(
list(list(width = 10, size = 2.5), list(width = 10, size = 2.5)),
rep(c(list(list(width = 2)), list(list(width = 2, overlay = TRUE, hjust = 0.15))), 8)
))
)
# 这里解释一下:
# id: 里面放的是你的列名。
# group:你对你data_long那些列的分组信息,这里我给Dataset列和Datatype列分别设置了分组,当然你可以把这两者当作一列
# name: 就是你图上每一列的label。我这里手动设置了18列的label,你也可以就直接用names(data_long)。
# geom: 你每列数据希望以什么形式呈现。那么Dataset,DataType以及rank这几列都是以文字形式呈现,而指标则以条形图形式呈现。还记得我们上面的data_long指标和其对应的排名是相邻的吗?所以这里我们用rep(c("AUC_palette",NA), length.out = 8)来实现间隔式的赋值。
# palette: 这里设置颜色信息。
# options: 图形参数。width表示该列在图上的宽度,size表示字体大小。后面overlay和hjust这两个参数就是用来设置rank的位置的。这俩参数表示rank信息可以覆盖在条形图上,通过hjust来调整它的水平位置。所以这也是为什么上面我一定要把data_long进行那样处理。
然后我们再创建分组信息和颜色信息:
# 设置分组以及其对应的颜色。其实这个column_group还能设置分组级别,做到层次分组。但这里我不展开说了, 感兴趣的可以去官网看demo。
column_groups <- tribble(
~group, ~palette,
"Dataset", "overall",
"DataType", "overall",
"AUC", "AUC_palette",
"ACC", "ACC_palette",
)
# 设置颜色信息
palettes <- tribble(
~palette, ~colours,
"overall", grDevices::colorRampPalette(rev(RColorBrewer::brewer.pal(9, "Greys")[-1]))(101),
"AUC_palette", grDevices::colorRampPalette(rev(RColorBrewer::brewer.pal(6, "Reds")))(101),
"ACC_palette", grDevices::colorRampPalette(rev(RColorBrewer::brewer.pal(9, "Blues")))(101)
)
以上都创建好后,我们就可以通过funky_heatmap()函数一键出图啦:
funky_heatmap(data = data_long, column_info = column_info, palettes = palettes,
add_abc = F, column_groups = column_groups,
position_args = position_arguments(
col_annot_offset = 3, col_space = 0.5, expand_xmin = 2, expand_ymin = 6))
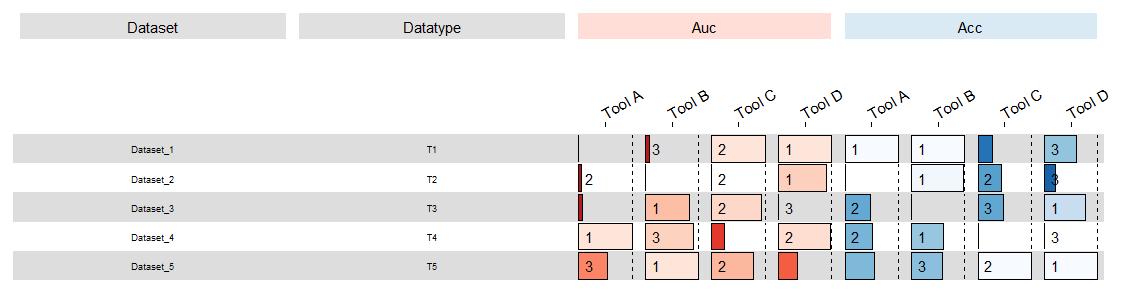
还是很简单的吧?回顾一下,其实复杂的地方就是数据处理那一块,如果对dplyr包不熟悉,写起代码来还是很头疼的(还好现在有GPT,虽然你让他写代码很多时候也很抽象,但总好过没有)。不过你自己看看你会发现,这个跟上面示例图差的很多呀,图例没有,column的label也在上方,那如果我一定要做的跟示例图一样该怎么办呢?换句话说,我想高度自定义这张图该怎么做呢?这个时候就得去研究它的底层代码了,为什么?因为很多你想自定义的东西它并没有给你弄,或者说弄好,教程也写的很浅(无奈笑)。由于我博客的篇幅限制,好像不能在同一篇博文里写全了,那进阶版的我就放到下一篇来写吧!

 苏公网安备 32050602011302号
苏公网安备 32050602011302号